

ベクトル検索とは?生成AI時代の新しい検索パラダイム
生成AIが普及する中、「ベクトル検索」という言葉を耳にする機会が急増している。ChatGPTやClaudeなどのLLM(大規模言語モデル)を企業データと連携させるRAG(Retrieval-Augmented Generation)において、ベクトル検索は中核技術として不可欠な存在だ。
ベクトル検索とは、「画像やテキストを数値化(ベクトル化)し、類似度を算出して情報の関連度を検索する手法」である。従来のキーワード検索が「文字列の一致」で検索するのに対し、ベクトル検索は「意味の類似性」で検索するという根本的な違いがある。
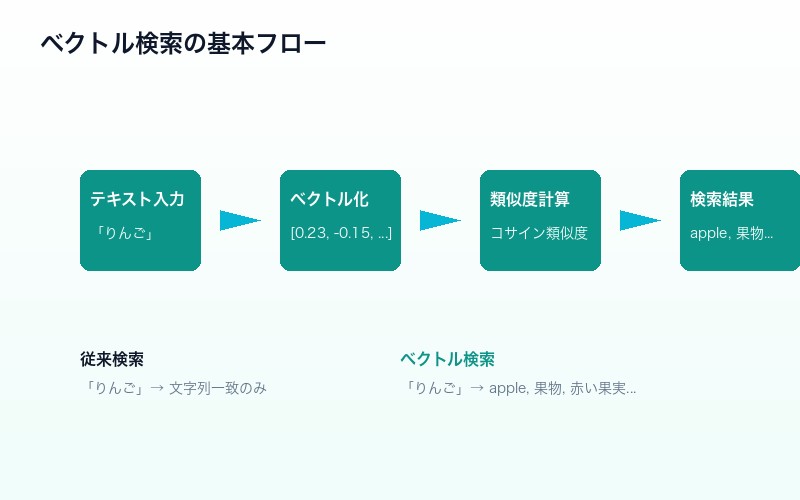
例えば、「りんご」というキーワードで検索した場合、従来のキーワード検索では「りんご」という文字列を含む文書しかヒットしない。しかしベクトル検索では、「apple」「果物」「赤い果実」といった意味的に関連する情報も検索結果に含めることができる。
なぜベクトル検索がRAGで重要なのか?
「RAGではいかに適切な情報を参照させるかが重要」という原則がある。生成AIの回答精度は、検索で取得する情報の質に直結するためだ。
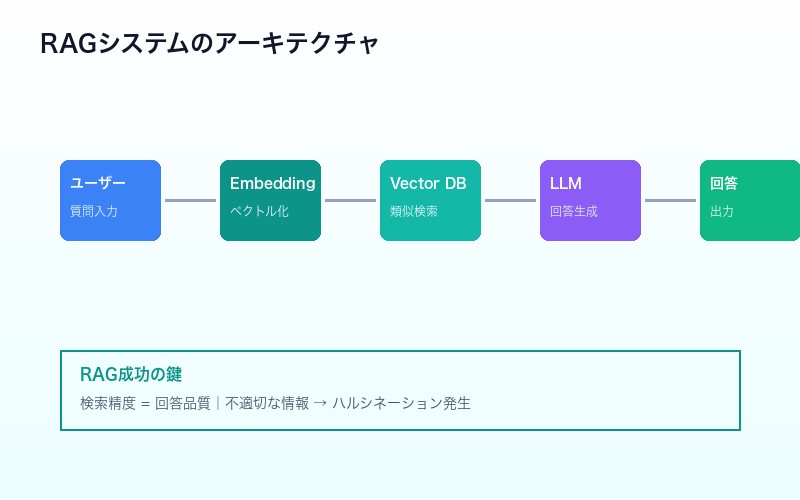
RAGシステムの基本的な流れは以下の通りだ:
- ユーザーの質問を受け取る
- 質問をベクトル化(埋め込み)する
- ベクトルDBから類似度の高い情報を検索
- 取得した情報をコンテキストとしてLLMに渡す
- LLMが回答を生成する
このプロセスにおいて、ステップ3の「検索精度」が回答品質を決定的に左右する。どれほど優秀なLLMを使用しても、検索で不適切な情報を取得すれば、回答の質は低下してしまう。
| 検索精度 | RAGへの影響 |
|---|---|
| 高精度 | 適切な情報がコンテキストに含まれ、正確な回答が生成される |
| 低精度 | 無関係な情報がコンテキストに混入し、幻覚(ハルシネーション)が発生 |
5つの検索アルゴリズム比較:キーワード検索からハイブリッド検索まで
現在のRAGシステムで使用される検索アルゴリズムは、大きく5つに分類できる。それぞれの特徴とトレードオフを理解することが、最適なシステム設計の第一歩だ。

| 検索方式 | 特徴 | 適用シーン |
|---|---|---|
| キーワード検索 | 文字列パターン照合(BM25など) | 固有名詞、型番、専門用語の検索 |
| ベクトル検索 | 意味的類似度に基づく検索 | 概念的な質問、曖昧なクエリ |
| ハイブリッド検索 | キーワード+ベクトルの組み合わせ | 汎用的なRAGシステム(推奨) |
| セマンティック検索 | キーワード結果の意味的再ランク付け | 検索結果の精度向上 |
| 高度な組み合わせ | 複数手法+リランカー活用 | 高精度が求められるエンタープライズ用途 |
特に注目すべきはハイブリッド検索だ。2026年現在、「RAGの精度向上に必須」とされており、ベクトル検索(意味)とキーワード検索(BM25など)を組み合わせることで、両者の強みを活かした検索が可能になる。
埋め込みモデル(Embedding Model)の仕組み
ベクトル検索の根幹を支えるのが埋め込みモデル(Embedding Model)だ。これは、テキストや画像を高次元のベクトル(数値の配列)に変換する技術である。
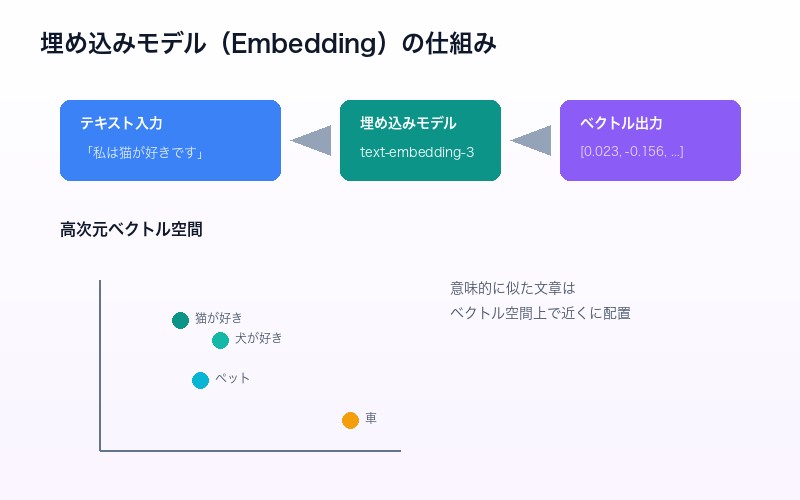
埋め込みの仕組み
例えば、「私は猫が好きです」という文章を埋め込みモデルに入力すると、以下のような数百〜数千次元のベクトルに変換される:
[0.023, -0.156, 0.892, 0.045, ..., 0.234] # 通常768〜3072次元のベクトル
このベクトルは、文章の「意味」を数値的に表現している。意味的に似た文章は、ベクトル空間上で近い位置に配置される。
主要な埋め込みモデル比較
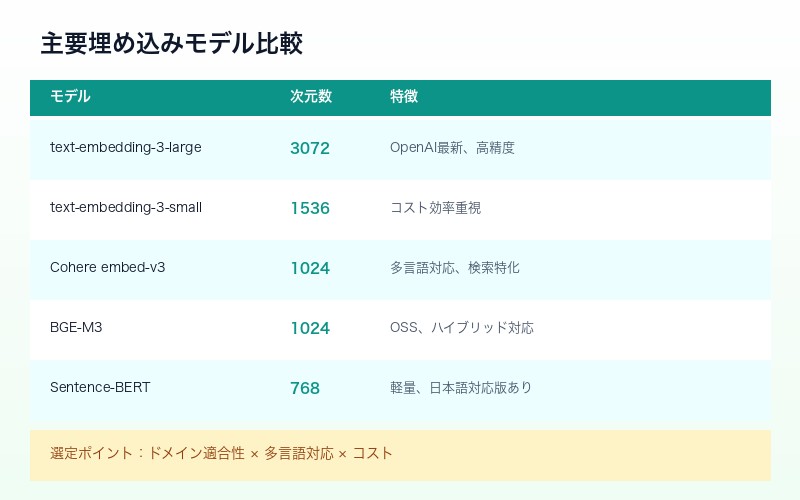
| モデル | 次元数 | 特徴 |
|---|---|---|
| text-embedding-3-large | 3072 | OpenAI最新、高精度、複雑な文脈理解 |
| text-embedding-3-small | 1536 | コスト効率重視、汎用用途 |
| Cohere embed-v3 | 1024 | 多言語対応、検索特化 |
| BGE-M3 | 1024 | オープンソース、多言語、ハイブリッド対応 |
| Sentence-BERT | 768 | オープンソース、軽量、日本語対応版あり |
Sentence Embedding vs Token Embedding
埋め込みには2つの主要なアプローチがある:
- Sentence Embedding:文全体の意味を単一のベクトルで表現。処理が高速だが、重要なキーワードが平均化されて埋もれる可能性
- Token Embedding:トークン(単語)単位でベクトルを生成。重要なキーワードの意味を個別に保持できるが、計算コストが高い
ベクトルデータベース(Vector DB)の選び方
生成されたベクトルを保存し、高速に検索するのがベクトルデータベースの役割だ。2026年現在、多くの選択肢が存在する。

| ベクトルDB | デプロイ | 特徴 |
|---|---|---|
| Pinecone | フルマネージド | 導入容易、スケーラブル、コスト高め |
| Qdrant | セルフホスト/クラウド | 高性能(Pineconeの4倍RPS)、フィルタリング強力 |
| Weaviate | セルフホスト/クラウド | GraphQL API、モジュール式アーキテクチャ |
| Chroma | ローカル/セルフホスト | 開発・プロトタイプ向け、LangChain統合 |
| Milvus | セルフホスト/クラウド | 大規模対応、GPU加速、エンタープライズ向け |
モノタロウの事例では、セルフホストQdrantがPinecone p2ポッドの4倍のRPS(スループット)と低レイテンシを実現したと報告されている。コストと性能のバランスを考慮した選択が重要だ。
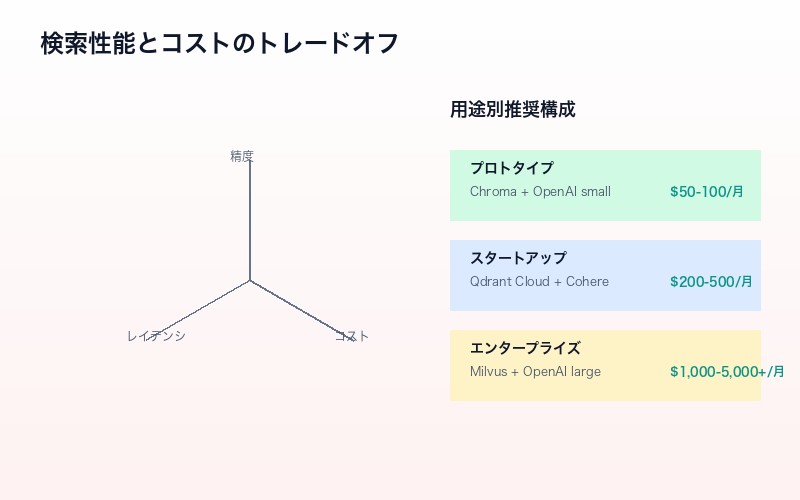
検索性能とコストのトレードオフ
「検索性能が高いほど、計算コストがかかる」というトレードオフは、ベクトル検索システム設計の根本的な課題だ。
コストに影響する要因
- 埋め込みモデルの選択:高次元モデルほど精度は高いが、計算・保存コストが増加
- ベクトルDB選択:フルマネージドは運用負荷が低いが、セルフホストより高コスト
- インデックス設定:精度を上げるとレイテンシ・メモリ使用量が増加
- 検索アルゴリズム:ハイブリッド検索は単一手法より計算量が多い
用途別推奨構成
| 用途 | 推奨構成 | 月額目安 |
|---|---|---|
| プロトタイプ・検証 | Chroma + OpenAI small | $50-100 |
| スタートアップ・中小 | Qdrant Cloud + Cohere | $200-500 |
| エンタープライズ | Milvus + OpenAI large + リランカー | $1,000-5,000+ |
RAG精度を左右する2つの要因
RAGの検索精度に影響する主な要因は、2つに集約される:

1. 埋め込みモデルの性能
データをベクトル化する際の「変換品質」が、検索精度の上限を決定する。モデル選定のポイントは:
- ドメイン適合性:一般用途か、特定分野(法律、医療など)特化か
- 多言語対応:日本語の処理精度は十分か
- 次元数:高次元ほど表現力は高いが、コストも増加
2. ANNインデックスのチューニング
ベクトルDBの検索アルゴリズム(ANN: Approximate Nearest Neighbor)の設定が、検索速度と精度のバランスを決める。主要なパラメータは:
- ef_construction:インデックス構築時の探索範囲(大きいほど高精度・低速)
- ef_search:検索時の探索範囲(大きいほど高精度・低速)
- M:各ノードの接続数(大きいほどメモリ消費増・高精度)
チャンキング戦略:データ分割の最適化
RAGシステムでは、長文ドキュメントを適切な単位(チャンク)に分割する必要がある。このチャンキング戦略が検索精度に大きく影響する。

| 戦略 | 特徴 | 適用シーン |
|---|---|---|
| 固定長分割 | 文字数や単語数で均等分割 | 構造化されていないテキスト |
| セマンティック分割 | 意味的なまとまりで分割 | 段落・セクション構造のある文書 |
| 再帰的分割 | 階層的に適切なサイズまで分割 | 多様な文書タイプの処理 |
| オーバーラップ分割 | チャンク間で一部重複させる | 文脈の断絶を防ぎたい場合 |
一般的に、チャンクサイズ256〜512トークン、オーバーラップ20〜50トークンが推奨される。ただし、ドメインやユースケースに応じた調整が必要だ。
2026年のトレンド:ベクトル検索の未来
ベクトル検索技術は急速に進化している。2026年以降の主要トレンドを整理する。
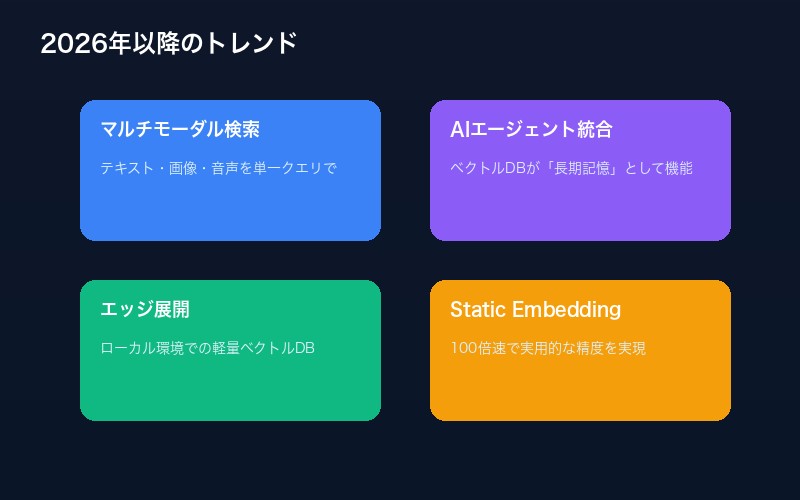
1. マルチモーダル検索の標準化
テキスト、画像、音声を単一のクエリで横断的に検索する技術が普及。CLIP、ImageBindなどのマルチモーダル埋め込みモデルの進化により、「画像で検索してテキストを取得」といった操作が一般的になる。
2. AIエージェントとの統合
ベクトルDBがAIエージェントの「長期記憶」として機能する設計パターンが主流に。エージェントが過去の対話履歴や学習した知識をベクトルDBに保存し、必要に応じて参照する。
3. エッジコンピューティングへの展開
LanceDBやChromaのパーシステントモードなど、ローカル環境で動作する軽量ベクトルDBの需要が増加。プライバシー要件の厳しいユースケースや、低レイテンシが求められるアプリケーションで活用される。
4. Static Embeddingの再評価
2025年以降、「100倍速で実用的な文章ベクトルを作れる」Static Embeddingモデルが登場。計算コストを大幅に削減しながら、実用的な精度を実現する選択肢として注目されている。
実装時の注意点とベストプラクティス
ベクトル検索システムを実装する際の重要なポイントをまとめる。

ベストプラクティス
- 段階的に導入:まずシンプルな構成で開始し、必要に応じて複雑化
- ベンチマークを実施:自社データで複数のモデル・DBを比較検証
- モニタリングを設定:検索精度、レイテンシ、コストを継続的に監視
- フィードバックループを構築:ユーザーの評価を収集し、継続改善
避けるべきアンチパターン
| アンチパターン | 問題点 |
|---|---|
| 最初から最高スペックを選択 | コスト超過、過剰設計 |
| ベンチマークなしで本番投入 | 精度問題の発見遅れ |
| チャンキング戦略の軽視 | 検索精度の低下 |
| モニタリングの省略 | 性能劣化の見逃し |
まとめ:ベクトル検索はRAG成功の鍵
ベクトル検索は、生成AI時代における情報アクセスの新しいパラダイムだ。従来のキーワード検索では実現できなかった「意味的な検索」を可能にし、RAGシステムの精度を決定的に左右する。

成功の鍵は、以下の3点に集約される:
- 適切な埋め込みモデルの選択:ドメイン、言語、コストを考慮
- ベクトルDBの最適化:用途に応じたDB選定とチューニング
- ハイブリッド検索の活用:ベクトル+キーワードの組み合わせ
データサイエンティストには「幅広い知識を持った上で、適切な判断を仰ぐ能力」が要求される。技術の進化は速いが、基本原理を理解していれば、新しいツールや手法にも対応できるはずだ。
参考リンク:
コメント