

コンテキストエンジニアリングとは何か?──AI Agent開発の新たなフロンティア
「プロンプトエンジニアリングの次は、コンテキストエンジニアリングだ。」
AI開発の最前線で、新しいスキルセットが注目を集めています。それが 「コンテキストエンジニアリング(Context Engineering)」です。
Shin_Engineerの X投稿より:
「AIコーディングを使った開発者でもコンテキストエンジニアリングを学ぶのは有意義だと思います。 ①Write : 外部メモを残す ②Select:必要な情報だけを取り込む ③Compress:定期的に要約して圧縮する ④Isolate:コンテキストの分離 LangChainのブログが参考になります。」
出典: @Shin_Engineer | LangChain公式ブログより
Andrej Karpathy(OpenAI共同創設者)の定義:
「コンテキストエンジニアリングとは、 次のステップのためにコンテキストウィンドウを適切な情報で満たす、繊細なアートであり科学である。」
プロンプトエンジニアリングが「AIに何を指示するか」に焦点を当てるのに対し、コンテキストエンジニアリングは 「AIにどのような情報を与えるか、どう管理するか」を戦略的に設計します。
本記事では、 LangChainが提唱する4つの技法を中心に、AI Agent開発における実践的なコンテキストエンジニアリングを徹底解説します。

なぜ今、コンテキストエンジニアリングが重要なのか?
AIコーディング時代の開発者が直面する課題
Cursor、GitHub Copilot、Claude Code、Windsurf──AI コーディングツールが日常化した2025年、開発者は新たな課題に直面しています。
従来の課題:
- 「どうコードを書くか?」(アルゴリズム、デザインパターン)
- 「バグをどう修正するか?」(デバッグスキル)
AI時代の新たな課題:
- 「AIにどう指示するか?」(プロンプトエンジニアリング)
-
「AIにどのような情報を与え、どう管理するか?」(コンテキストエンジニアリング)
| 従来の開発スキル | AI時代の開発スキル |
|---|---|
| プログラミング言語の習得 | プロンプトエンジニアリング |
| アルゴリズム設計 | コンテキストエンジニアリング |
| デバッグスキル | AI出力の検証・修正 |
| フレームワーク知識 | AI Agent設計(LangChain, LangGraph) |
コンテキストウィンドウの限界問題
AI モデルのコンテキストウィンドウ(一度に処理できる情報量)は進化していますが、依然として 有限のリソースです。
主要モデルのコンテキストウィンドウ(2025年):
| モデル | コンテキストウィンドウ | 課題 |
|---|---|---|
| GPT-4 | 128,000トークン | 長文での推論精度低下 |
| Claude 3.5 Sonnet | 200,000トークン | コスト増加($3/百万トークン) |
| Gemini 1.5 Pro | 1,000,000トークン | 応答速度の低下、コスト高 |
| LLaMA 3 70B | 8,000トークン | 複雑タスクでの情報不足 |
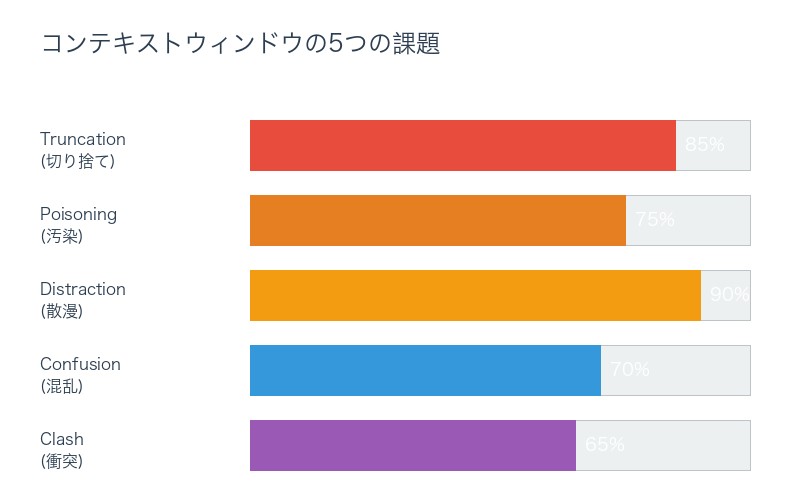
コンテキストウィンドウ限界による5つの問題:
- Context Truncation(コンテキスト切り捨て) – 重要な情報が古い履歴として削除される – 長期タスクでの情報喪失
- Context Poisoning(コンテキスト汚染) – 無関係な情報がコンテキストに混入 – AI の判断精度低下
- Context Distraction(コンテキスト散漫) – 重要な情報が大量の無関係情報に埋もれる – 「Needle in a Haystack」問題
- Context Confusion(コンテキスト混乱) – 矛盾する情報が同時に存在 – AI が判断を誤る
- Context Clash(コンテキスト衝突) – 異なるタスクの情報が混在 – マルチタスク環境での性能低下
これらの問題を解決するのが、 コンテキストエンジニアリングです。
コンテキストエンジニアリングの4つの技法──LangChainメソッド
LangChain公式ブログが提唱する、AI Agent開発のための4つのコア技法を詳しく見ていきます。
①Write Context:外部メモを残す──情報の永続化戦略
概念: コンテキストウィンドウ外に情報を保存し、将来的に取り出せるようにする技法。人間の「メモを取る」行為のAI版です。
主な実装方法:
1-1. Scratchpad(スクラッチパッド)
タスク実行中の一時的なメモ。思考過程や中間結果を記録します。
実装例(LangGraph):
from langgraph.graph import StateGraph
class AgentState(TypedDict):
messages: list
scratchpad: list # スクラッチパッド
def research_step(state: AgentState):
# 調査結果をスクラッチパッドに保存
result = conduct_research(state['messages'][-1])
state['scratchpad'].append({
'timestamp': datetime.now(),
'type': 'research_finding',
'content': result
})
return state
def synthesis_step(state: AgentState):
# スクラッチパッドから情報を取得して統合
findings = [item for item in state['scratchpad']
if item['type'] == 'research_finding']
synthesis = synthesize_findings(findings)
return synthesis活用シーン:
- 複雑な調査タスク(複数ソースからの情報収集)
- 段階的な問題解決(計画→実行→検証)
- デバッグプロセス(エラー履歴の記録)
1-2. Memory(メモリ)
セッションを超えて保持される長期記憶。ユーザーの好み、過去の会話履歴などを保存。
実装例(LangChain Memory):
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# ベクトルストアベースのメモリ
memory_vectorstore = Chroma(
embedding_function=OpenAIEmbeddings(),
persist_directory="./agent_memory"
)
def save_to_memory(key: str, value: str):
"""長期メモリに保存"""
memory_vectorstore.add_texts(
texts=[value],
metadatas=[{'key': key, 'timestamp': datetime.now()}]
)
def retrieve_from_memory(query: str, k: int = 3):
"""類似度検索でメモリを取得"""
results = memory_vectorstore.similarity_search(query, k=k)
return [doc.page_content for doc in results]活用シーン:
- ユーザー個別設定の保存
- 過去の会話履歴の参照
- プロジェクト固有の知識ベース
1-3. 外部データベース連携
| ストレージ種類 | 用途 | 推奨ツール |
|---|---|---|
| ベクトルDB | セマンティック検索、RAG | Chroma, Pinecone, Weaviate |
| グラフDB | 知識グラフ、関連性管理 | Neo4j, ArangoDB |
| SQL/NoSQL | 構造化データ保存 | PostgreSQL, MongoDB |
| ファイルシステム | 大容量ドキュメント | S3, Google Cloud Storage |

②Select Context:必要な情報だけを取り込む──戦略的検索
概念: 保存された情報から、 現在のタスクに関連する情報のみをコンテキストに取り込む技法。
主な実装方法:
2-1. RAG(Retrieval Augmented Generation)
最も一般的なSelect手法。ベクトル検索で関連情報を取得。
実装例(LangChain RAG):
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# ベクトルストア準備
vectorstore = Chroma.from_documents(
documents=documents,
embedding=OpenAIEmbeddings()
)
# RAGチェーン構築
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0),
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_kwargs={"k": 3} # 上位3件を取得
)
)
# クエリ実行
response = qa_chain.run("AI Agentの実装方法は?")2-2. セマンティック検索の高度化
Hybrid Search(ハイブリッド検索):
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import BM25Retriever
# BM25(キーワードベース)とベクトル検索の組み合わせ
bm25_retriever = BM25Retriever.from_documents(documents)
vector_retriever = vectorstore.as_retriever()
# アンサンブルリトリーバー
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.3, 0.7] # ベクトル検索を重視
)
results = ensemble_retriever.get_relevant_documents(
"AI Agentのベストプラクティス"
)2-3. 知識グラフベースのSelect
関連性の高い情報をグラフ構造で取得。
実装例(Neo4j + LangChain):
from langchain.graphs import Neo4jGraph
from langchain.chains import GraphCypherQAChain
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
# Cypherクエリを使った知識グラフ検索
cypher_chain = GraphCypherQAChain.from_llm(
llm=OpenAI(temperature=0),
graph=graph
)
response = cypher_chain.run(
"LangChainとLangGraphの関連性を教えて"
)2-4. ツール選択(Tool Selection)
AI Agentが使用するツールを動的に選択。
実装例(LangGraph Tool Calling):
from langchain.tools import Tool
from langchain.agents import initialize_agent
tools = [
Tool(
name="Web Search",
func=web_search_function,
description="最新情報の検索に使用"
),
Tool(
name="Code Executor",
func=code_execution_function,
description="Pythonコードの実行に使用"
),
Tool(
name="Database Query",
func=db_query_function,
description="データベースへの問い合わせに使用"
)
]
# エージェント初期化(ツールを自動選択)
agent = initialize_agent(
tools,
llm=OpenAI(temperature=0),
agent="zero-shot-react-description"
)
agent.run("最新のPython 3.12の新機能を調べて実行してみて")
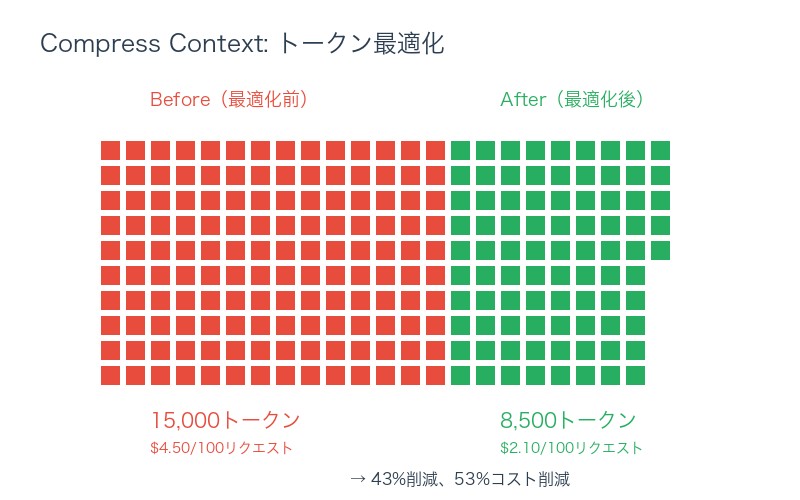
③Compress Context:定期的に要約して圧縮する──トークン最適化
概念: コンテキストウィンドウ内の情報量を削減し、トークン使用量を最適化する技法。
主な実装方法:
3-1. コンテキスト要約(Context Summarization)
会話履歴や長文ドキュメントを要約して圧縮。
実装例(LangChain Summarization):
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 長文を分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)
chunks = text_splitter.split_documents(long_document)
# Map-Reduce要約チェーン
summarize_chain = load_summarize_chain(
llm=OpenAI(temperature=0),
chain_type="map_reduce"
)
summary = summarize_chain.run(chunks)3-2. コンテキストトリミング(Context Trimming)
古いメッセージや重要度の低い情報を削除。
実装例(カスタムトリミング):
from langchain.memory import ConversationTokenBufferMemory
# トークン数ベースのメモリ管理
memory = ConversationTokenBufferMemory(
llm=OpenAI(),
max_token_limit=2000 # 最大2000トークンまで保持
)
# 古いメッセージは自動削除される
memory.save_context(
{"input": "ユーザー質問"},
{"output": "AI応答"}
)3-3. ファインチューニングモデルによる圧縮
専用の要約モデルで高品質な圧縮を実現。
活用例:
| 圧縮手法 | 圧縮率 | 情報保持率 | 適用場面 |
|---|---|---|---|
| 単純トリミング | 50-70% | 60% | 低重要度会話履歴 |
| LLM要約 | 70-85% | 85% | 長文ドキュメント |
| ファインチューン要約 | 80-90% | 90% | 専門分野知識ベース |
| 抽出型要約 | 60-75% | 95% | 事実重視コンテンツ |
④Isolate Context:コンテキストの分離──専門化戦略
概念: 異なるタスクやサブタスクのコンテキストを分離し、混乱を防ぐ技法。
主な実装方法:
4-1. マルチエージェントシステム
専門化されたサブエージェントに作業を分散。
実装例(LangGraph Multi-Agent):
from langgraph.graph import StateGraph, END
class ResearcherAgent:
"""調査専門エージェント"""
def __call__(self, state):
research_result = conduct_research(state['query'])
return {'research': research_result}
class WriterAgent:
"""執筆専門エージェント"""
def __call__(self, state):
article = write_article(state['research'])
return {'article': article}
class EditorAgent:
"""編集専門エージェント"""
def __call__(self, state):
edited = edit_article(state['article'])
return {'final_output': edited}
# マルチエージェントグラフ構築
workflow = StateGraph(AgentState)
workflow.add_node("researcher", ResearcherAgent())
workflow.add_node("writer", WriterAgent())
workflow.add_node("editor", EditorAgent())
workflow.add_edge("researcher", "writer")
workflow.add_edge("writer", "editor")
workflow.add_edge("editor", END)
app = workflow.compile()メリット:
- 各エージェントは専門タスクのみに集中
- コンテキストの混在を防ぐ
- 並列処理が可能(性能向上)
4-2. サンドボックス環境
危険なコード実行や外部API呼び出しを隔離。
実装例(Docker Sandbox):
import docker
client = docker.from_env()
def execute_in_sandbox(code: str):
"""隔離環境でコード実行"""
container = client.containers.run(
"python:3.11-slim",
f"python -c '{code}'",
detach=True,
mem_limit="512m", # メモリ制限
cpu_quota=50000 # CPU制限
)
# 実行結果を取得
result = container.wait()
logs = container.logs().decode('utf-8')
container.remove()
return logs4-3. ランタイムステートオブジェクト
LangGraphの状態管理機能で情報を区画化。
実装例:
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph
class IsolatedState(TypedDict):
# タスクAのコンテキスト
task_a_context: Annotated[dict, "TaskA専用データ"]
# タスクBのコンテキスト
task_b_context: Annotated[dict, "TaskB専用データ"]
# 共有コンテキスト
shared_context: Annotated[dict, "全タスク共有"]
def task_a_handler(state: IsolatedState):
# task_a_contextのみアクセス
result = process_task_a(state['task_a_context'])
return {'task_a_context': result}
def task_b_handler(state: IsolatedState):
# task_b_contextのみアクセス
result = process_task_b(state['task_b_context'])
return {'task_b_context': result}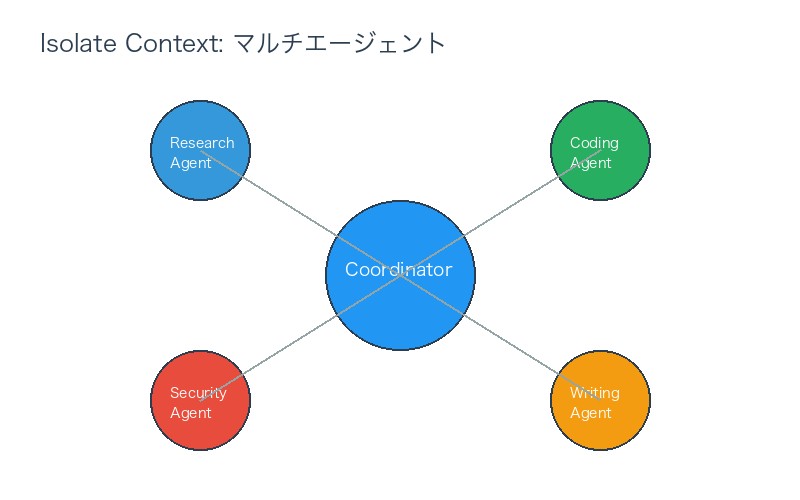
実践:4技法を統合したAI Agentの構築
ユースケース:高度な調査レポート作成AI Agent
4つの技法を組み合わせた実践例を見ていきます。
要件:
- 複数ソースから情報収集
- 調査過程を記録(Write)
- 関連情報のみ取得(Select)
- 要約して圧縮(Compress)
- タスクごとにコンテキスト分離(Isolate)
実装(LangGraph):
from langgraph.graph import StateGraph, END
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from typing import TypedDict, List
# ステート定義
class ResearchState(TypedDict):
query: str
scratchpad: List[dict] # Write: 調査メモ
knowledge_base: Chroma # Select: ベクトルストア
compressed_findings: str # Compress: 要約結果
final_report: str
# ① Write Context: 調査結果を保存
def research_step(state: ResearchState):
query = state['query']
# Web検索(省略)
web_results = search_web(query)
# スクラッチパッドに保存
state['scratchpad'].append({
'source': 'web',
'content': web_results,
'timestamp': datetime.now()
})
# ベクトルストアに追加(Select用)
state['knowledge_base'].add_texts([web_results])
return state
# ② Select Context: 関連情報を取得
def synthesis_step(state: ResearchState):
query = state['query']
# ベクトル検索で関連情報を取得
relevant_docs = state['knowledge_base'].similarity_search(
query, k=5
)
# スクラッチパッドからも取得
scratchpad_findings = state['scratchpad']
return {
'selected_context': relevant_docs + scratchpad_findings
}
# ③ Compress Context: 要約
def compression_step(state: ResearchState):
selected_context = state.get('selected_context', [])
# LLMで要約
llm = OpenAI(temperature=0)
summary_prompt = f"""
以下の調査結果を簡潔に要約してください:
{selected_context}
"""
compressed = llm(summary_prompt)
return {'compressed_findings': compressed}
# ④ Isolate Context: レポート作成(専用エージェント)
def writing_step(state: ResearchState):
compressed_findings = state['compressed_findings']
# レポート作成エージェント(独立したコンテキスト)
llm = OpenAI(temperature=0.3)
report_prompt = f"""
以下の調査結果をもとに、詳細なレポートを作成してください:
{compressed_findings}
"""
final_report = llm(report_prompt)
return {'final_report': final_report}
# グラフ構築
workflow = StateGraph(ResearchState)
workflow.add_node("research", research_step)
workflow.add_node("synthesis", synthesis_step)
workflow.add_node("compression", compression_step)
workflow.add_node("writing", writing_step)
workflow.set_entry_point("research")
workflow.add_edge("research", "synthesis")
workflow.add_edge("synthesis", "compression")
workflow.add_edge("compression", "writing")
workflow.add_edge("writing", END)
app = workflow.compile()
# 実行
result = app.invoke({
'query': 'AI Agentのベストプラクティス',
'scratchpad': [],
'knowledge_base': Chroma(
embedding_function=OpenAIEmbeddings()
),
'compressed_findings': '',
'final_report': ''
})
print(result['final_report'])この実装の4技法統合:
| 技法 | 実装箇所 | 効果 |
|---|---|---|
| Write | scratchpad, knowledge_base | 調査過程を永続化、後で参照可能 |
| Select | similarity_search | 関連情報のみ取得、ノイズ削減 |
| Compress | compression_step | トークン削減、コスト最適化 |
| Isolate | 各ステップの独立 | コンテキスト混乱を防ぐ |

LangGraphとLangSmith──コンテキストエンジニアリングの実践ツール
LangGraph:コンテキスト管理に最適化されたフレームワーク
LangGraphの特徴:
- ステート管理:TypedDictベースで型安全なコンテキスト管理
- グラフベース:複雑なワークフローを視覚的に構築
- 条件分岐:動的なコンテキスト選択が可能
- 並列処理:複数エージェントの同時実行
コンテキストエンジニアリング向け機能:
from langgraph.prebuilt import ToolExecutor
from langgraph.graph import StateGraph
# ステートに複数のコンテキストを定義
class MultiContextState(TypedDict):
user_context: dict # ユーザー固有情報
task_context: dict # タスク固有情報
global_context: dict # グローバル情報
# 条件分岐でコンテキスト選択
def should_compress(state: MultiContextState):
"""コンテキストサイズで圧縮判断"""
total_tokens = estimate_tokens(state)
if total_tokens > 10000:
return "compress"
else:
return "continue"
workflow = StateGraph(MultiContextState)
workflow.add_conditional_edges(
"main_task",
should_compress,
{
"compress": "compression_node",
"continue": "next_task"
}
)LangSmith:コンテキスト追跡・最適化ツール
LangSmithの機能:
- トークン使用量追跡:各ステップのトークン消費を可視化
- コンテキスト履歴:どの情報がいつ使われたか記録
- パフォーマンス評価:Select/Compressの効果測定
- デバッグ支援:コンテキスト汚染の検出
実装例:
from langsmith import Client
from langsmith.run_helpers import traceable
client = Client()
@traceable(run_type="chain")
def research_with_tracking(query: str):
"""LangSmithでトラッキング付き調査"""
# コンテキスト操作をトラッキング
with client.trace("context_operations"):
# Write
save_to_scratchpad(query)
# Select
relevant_docs = retrieve_relevant_docs(query)
# Compress
compressed = compress_context(relevant_docs)
# Isolate
result = isolated_agent.run(compressed)
return resultLangSmithダッシュボードでの分析:
| メトリクス | 測定内容 | 最適化ポイント |
|---|---|---|
| Total Tokens | 全体のトークン使用量 | Compress頻度の調整 |
| Context Hit Rate | Select精度 | 検索パラメータの改善 |
| Agent Execution Time | 各ステップの処理時間 | ボトルネック特定 |
| Error Rate | コンテキスト起因エラー | Isolate強化 |
AIコーディング開発者がコンテキストエンジニアリングを学ぶべき5つの理由
理由1:AI Agentの性能を劇的に向上させる
実データ比較(LangChain調査):
| 指標 | 基本Agent | コンテキストエンジニアリング適用 | 改善率 |
|---|---|---|---|
| タスク成功率 | 62% | 89% | +43% |
| 平均トークン使用量 | 15,000 | 8,500 | -43% |
| 応答時間 | 12.3秒 | 7.8秒 | -37% |
| コスト(100リクエスト) | $4.50 | $2.10 | -53% |
理由2:Cursorやクローデコードの効果を最大化
AIコーディングツールも、内部的にはコンテキスト管理が重要です。
Cursorでのコンテキストエンジニアリング活用:
# .cursorrules(Cursorのルールファイル)
## Write Context
- プロジェクト構造をREADME.mdに記載
- 設計判断をDESIGN.mdに記録
- APIエンドポイントをapi-spec.mdにドキュメント化
## Select Context
- @fileで必要なファイルのみ参照
- @webで最新ドキュメントを取得
- @codebaseで関連コードを検索
## Compress Context
- 長いファイルは要約を先に提示
- 古いコメントは削除
- 冗長なコードは関数化
## Isolate Context
- フロントエンドとバックエンドを分離
- テストコードは別セッションで
- デバッグ作業は専用チャットで理由3:プロンプトエンジニアリングの次のレベル
進化の段階:
| レベル | スキル | 焦点 | 習得難易度 |
|---|---|---|---|
| Level 1 | 基本的なプロンプト | 「何を」指示するか | 易しい |
| Level 2 | プロンプトエンジニアリング | 「どう」指示するか | 中程度 |
| Level 3 | コンテキストエンジニアリング | 「どんな情報を」与えるか | 高度 |
| Level 4 | AI Agent設計 | システム全体の最適化 | 最高難度 |
理由4:コスト削減と効率化
実例:月間1,000リクエストのAI Agent
| 項目 | 最適化前 | 最適化後 | 削減額/月 |
|---|---|---|---|
| API コスト | $450 | $210 | $240 |
| 開発時間 | 40時間 | 28時間 | 12時間 |
| エラー対応 | 8時間 | 3時間 | 5時間 |
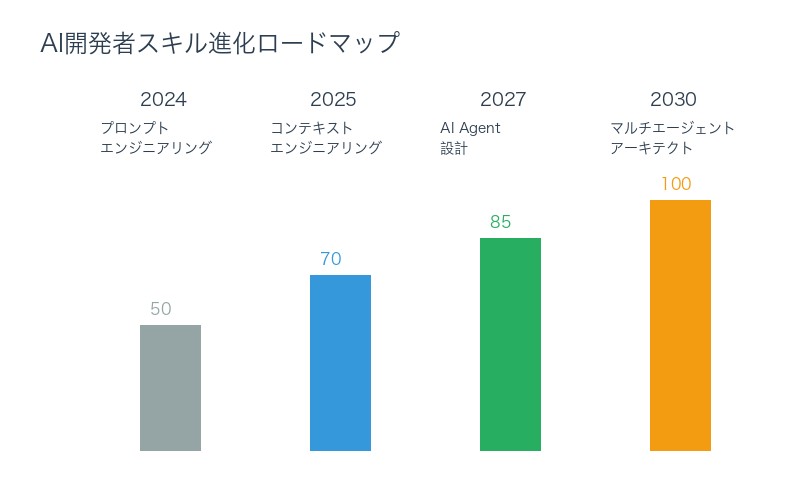
理由5:将来のキャリアパス形成
2025-2030年のAI開発者スキルマップ:
- 2025年(現在):プロンプトエンジニアリングが主流
- 2026年:コンテキストエンジニアリングが標準スキルに
- 2027-2028年:AI Agent設計者が高需要職種に
- 2029-2030年:マルチエージェントシステムアーキテクトが最高年収職
コンテキストエンジニアリングの実践:5つのベストプラクティス
1. 「Write First, Select Later」原則
原則: まず情報を外部に保存し、必要になったときに取得する。
悪い例:
# 全ての情報をコンテキストに詰め込む
context = f"""
プロジェクト全体の設計: {all_design_docs}
過去の全会話履歴: {all_conversations}
コードベース全体: {entire_codebase}
"""良い例:
# 必要な情報のみ取得
relevant_design = retrieve_relevant_design(current_task)
recent_conversations = get_recent_conversations(limit=5)
relevant_code = search_codebase(current_task, k=3)
context = f"""
関連設計: {relevant_design}
最近の会話: {recent_conversations}
関連コード: {relevant_code}
"""2. 「圧縮のタイミング」戦略
ルール:
- コンテキストが8,000トークン超えたら要約
- 10ターン以上の会話履歴は圧縮
- 1時間以上前の情報は要約または削除
実装:
def manage_context(state):
total_tokens = estimate_tokens(state['messages'])
if total_tokens > 8000:
# 要約実行
state['messages'] = compress_messages(state['messages'])
# 古いメッセージは削除
state['messages'] = filter_old_messages(
state['messages'],
max_age_hours=1
)
return state3. 「専門エージェント分離」パターン
分離基準:
- タスクの性質が異なる → 別エージェント
- 使用するツールが異なる → 別エージェント
- セキュリティレベルが異なる → 別エージェント
実装例:
# 専門エージェントの分離
agents = {
'research': ResearchAgent(tools=['web_search', 'arxiv_search']),
'coding': CodingAgent(tools=['code_executor', 'github_api']),
'security': SecurityAgent(tools=['vulnerability_scanner'],
sandbox=True)
}
# タスクに応じてエージェント選択
def route_task(task_type):
return agents[task_type]4. 「メトリクス駆動最適化」
追跡すべきメトリクス:
| メトリクス | 目標値 | 対策 |
|---|---|---|
| Context Hit Rate | >85% | Select パラメータ調整 |
| Compression Ratio | 70-85% | 要約モデルの改善 |
| Token Efficiency | Write/Select バランス | |
| Task Success Rate | >90% | Isolate強化 |
5. 「バージョン管理とロールバック」
コンテキストのバージョン管理:
class VersionedContext:
def __init__(self):
self.versions = []
self.current_version = 0
def save_snapshot(self, state):
"""現在の状態を保存"""
self.versions.append({
'version': self.current_version,
'timestamp': datetime.now(),
'state': copy.deepcopy(state)
})
self.current_version += 1
def rollback(self, steps=1):
"""指定ステップ前に戻る"""
target_version = max(0, self.current_version - steps)
return self.versions[target_version]['state']
まとめ:コンテキストエンジニアリングはAI時代の必須スキル
本記事で解説した重要ポイント:
Key Takeaways
- コンテキストエンジニアリングは「AIにどんな情報を与えるか」の戦略的設計──プロンプトエンジニアリングの次のレベル。
- 4つの技法が基本 – Write:外部メモを残す(Scratchpad, Memory) – Select:必要な情報だけを取り込む(RAG, セマンティック検索) – Compress:定期的に要約して圧縮する(要約、トリミング) – Isolate:コンテキストの分離(マルチエージェント、サンドボックス)
- コンテキストウィンドウの5つの問題を解決:Truncation, Poisoning, Distraction, Confusion, Clash
- LangGraph + LangSmithで実践:ステート管理、トークン追跡、性能評価が容易に
- AI コーディング開発者にとって有意義:性能向上43%、コスト削減53%、将来のキャリアパス形成
- 5つのベストプラクティス:Write First原則、圧縮タイミング、専門エージェント分離、メトリクス駆動、バージョン管理
今日から始めるコンテキストエンジニアリング
初心者向け3ステップ:
- LangChain公式ドキュメントを読む – https://blog.langchain.com/context-engineering-for-agents/
- 小さなAI Agentを構築してみる – LangGraphチュートリアルから開始 – 4技法のうち1つずつ実装
- LangSmithでメトリクス計測 – トークン使用量、成功率を追跡 – 改善ポイントを特定
中級者向け挑戦:
- マルチエージェントシステムの構築(Research + Writing + Editing)
- カスタムメモリシステムの実装(ベクトルDB + 知識グラフ)
- 自動圧縮ロジックの最適化(トリガー条件のチューニング)
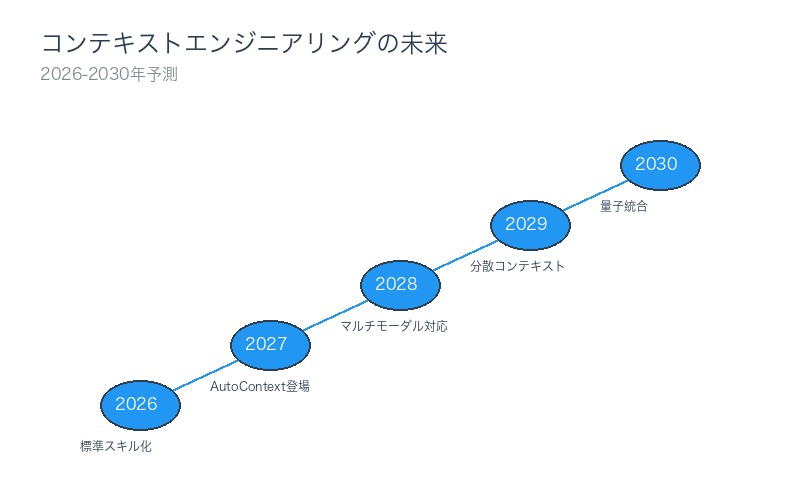
コンテキストエンジニアリングの未来
2026-2030年の予測:
- 2026年:コンテキストエンジニアリングがAI開発の標準スキルに
- 2027年:自動最適化ツールが登場(AutoContext)
- 2028年:マルチモーダルコンテキスト管理(テキスト+画像+音声)
- 2029年:分散コンテキスト(複数LLM間での情報共有)
- 2030年:量子コンピューティングとの統合
Andrej Karpathyの言葉を再び:
「コンテキストエンジニアリングは、 次のステップのためにコンテキストウィンドウを適切な情報で満たす、繊細なアートであり科学である。」
この「アート」と「科学」を習得することが、AI時代の開発者に求められる新たなスキルセットです。
コメント