

ウィキペディアがAI企業からの「正式報酬」を獲得した衝撃
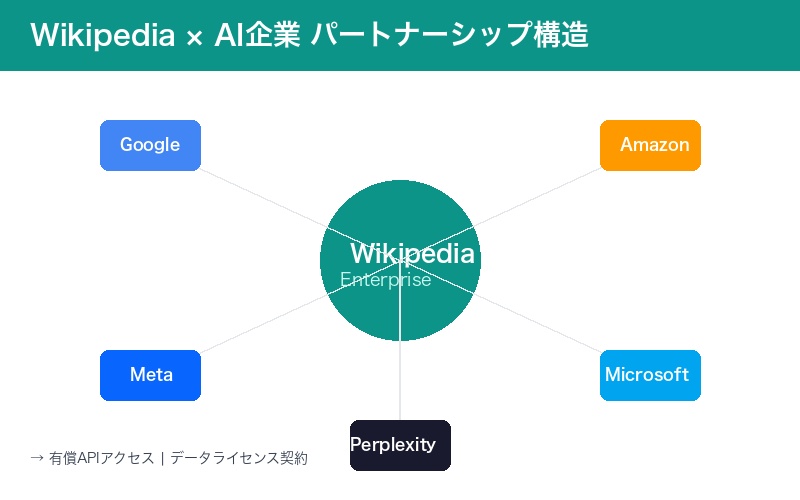
2026年1月15日、ウィキペディアの25周年を記念して、Wikimedia Foundationが衝撃的な発表を行った。Amazon、Meta、Microsoft、Mistral AI、Perplexityの5社が、新たに「Wikimedia Enterprise」の有償パートナーとなったのだ。
これは単なるビジネス契約ではない。「データは新たな金である」という時代の到来を象徴する出来事だ。AIの急速な発展により、クリーンで人間による検証済みのトレーニングデータへの需要が爆発的に増加している。そして、世界で最も信頼される知識データベースであるWikipediaが、ついにその価値に見合った報酬を受け取ることになった。
この記事では、Wikimedia Enterpriseの仕組み、参加企業の詳細、そしてこの動きがAI業界とSEOにもたらす影響を詳しく解説する。
Wikimedia Enterpriseとは:有償データアクセスの新モデル
Wikimedia Enterpriseは、Wikipediaのデータを大規模に再利用・配信する事業者向けに、高信頼・高スループットなAPIアクセスを有償で提供するサービスだ。
| API種類 | 機能 | 用途 |
|---|---|---|
| On-demand API | リクエスト時に最新記事を返却 | リアルタイム検索 |
| Snapshot API | 全言語のWikipediaファイルを毎時更新で提供 | AIモデル学習 |
| Realtime API | 更新をリアルタイムでストリーミング | 最新情報の即座反映 |
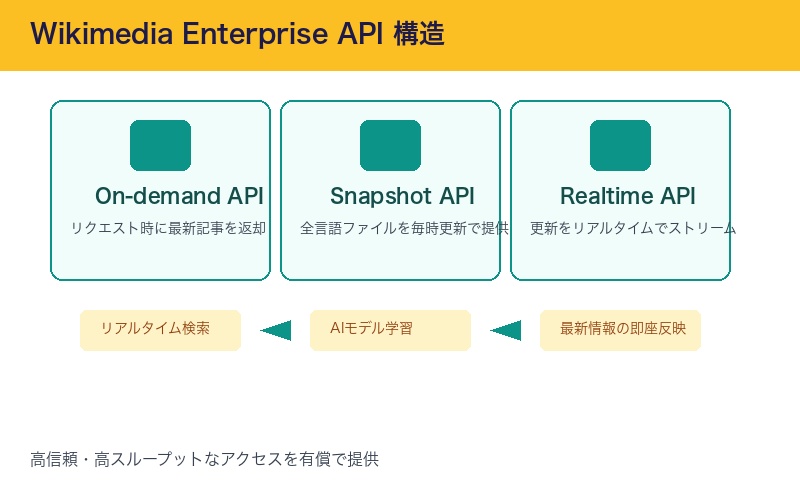
重要なのは、Enterpriseが単なる「寄付」ではなく、企業のデータ需要に合わせた「量と速度」で提供する設計になっていることだ。AIモデルや検索回答プロダクトは、更新頻度が高い情報を大量に取り込みたい一方で、無秩序な取得はサーバー負荷や運用コストを押し上げる。
参加企業一覧:テック巨人たちの顔ぶれ
今回発表された新パートナー5社に加え、2022年から参加しているGoogleを含めると、AI業界の主要プレイヤーがほぼ網羅される形となった。
| 企業 | 参加時期 | 主なAI製品 |
|---|---|---|
| 2022年〜 | Gemini、Google Search AI | |
| Amazon | 2026年1月〜 | Alexa、AWS AI Services |
| Meta | 2026年1月〜 | Llama、Meta AI |
| Microsoft | 2026年1月〜 | Copilot、Bing AI |
| Mistral AI | 2026年1月〜 | Mistral Large、Le Chat |
| Perplexity | 2026年1月〜 | Perplexity AI検索 |
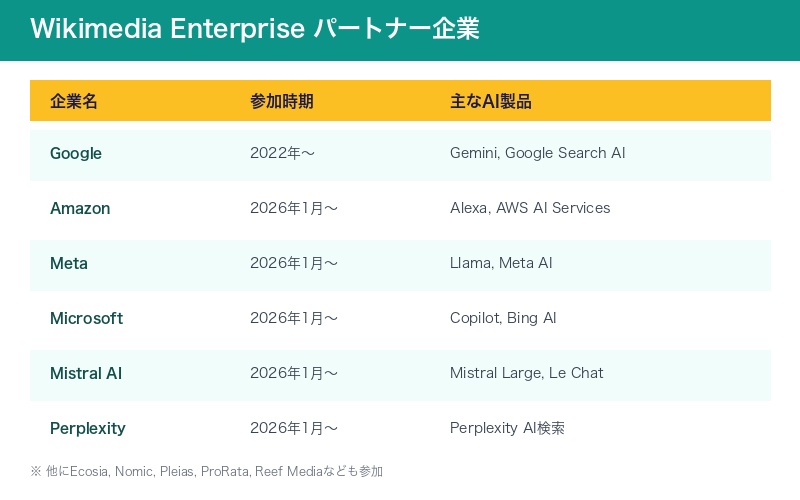
その他のパートナーには、Ecosia、Nomic、Pleias、ProRata、Reef Mediaなども含まれている。
背景:なぜWikipediaは「課金」に踏み切ったのか
この決断の背景には、深刻な運営上の課題があった。
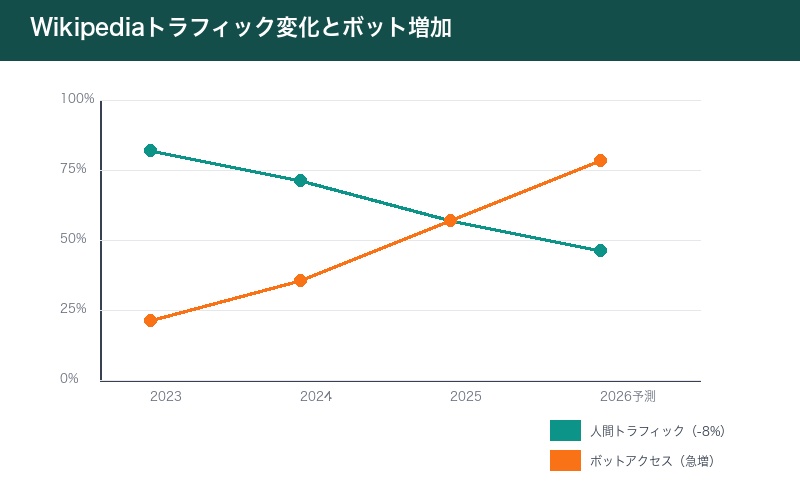
人間のトラフィック8%減少
Wikimedia Foundationは2025年11月、AIによる無断スクレイピングの停止と有償APIの利用を呼びかけた。その理由は明確だ。
- AIの普及により、人間によるページビューが8%減少
- ボットによるアクセスが急増し、サーバー負荷が深刻化
- 検出を回避するために偽装されたボットも増加
- 編集者や寄付の減少が懸念される状況
CEO Maryana Iskander氏のコメント
Wikimedia Foundation CEO Maryana Iskander氏:
「私たちのインフラは無料ではありません。個人とテック企業の両方がWikipediaからデータを引き出せるようにするサーバーやその他のインフラを維持するには、お金がかかります。」
Jimmy Walesの見解
Wikipedia創設者のJimmy Wales氏も、このパートナーシップを「実用的な解決策」として歓迎している。彼は、Wikipediaで訓練されたモデルが人間の編集プロセスの恩恵を受けていることを指摘。この編集プロセスは、誤情報をフィルタリングし、検証基準を強制するものだ。
Perplexityの特別な貢献
興味深いことに、Perplexityは単なる有償パートナーシップを超えた貢献を表明した。

Perplexityの発表:
「Wikipediaの25周年を記念して、Perplexityは編集者たちと共有するための2,500席のPerplexity Enterpriseを贈呈します。私たちがWikimedia Enterpriseの顧客になったのは、財団の『知識を誰もが無料でアクセスできるようにする』というミッションを誇りを持って支援したいからです。」
これは年間数百万円相当の価値があり、Wikipedia編集者のリサーチ効率向上に貢献するものだ。
再帰的な知識検証の時代へ
しかし、この貢献の本質はツールの提供だけではない。Wikipedia編集者が「AIを使って事実確認をする」という新しいワークフローの実験でもあるのだ。
考えてみてほしい。AIが生成した情報の真偽を、AIで確認する——この再帰的な構造は、今後の知識検証のスタンダードになる可能性がある。Perplexityで得た情報をWikipedia編集者が検証し、その検証済み情報がWikipediaに反映され、そのWikipediaデータでまたAIが学習する。これは「人間とAIの協調による知識の精緻化サイクル」の始まりと言えるだろう。
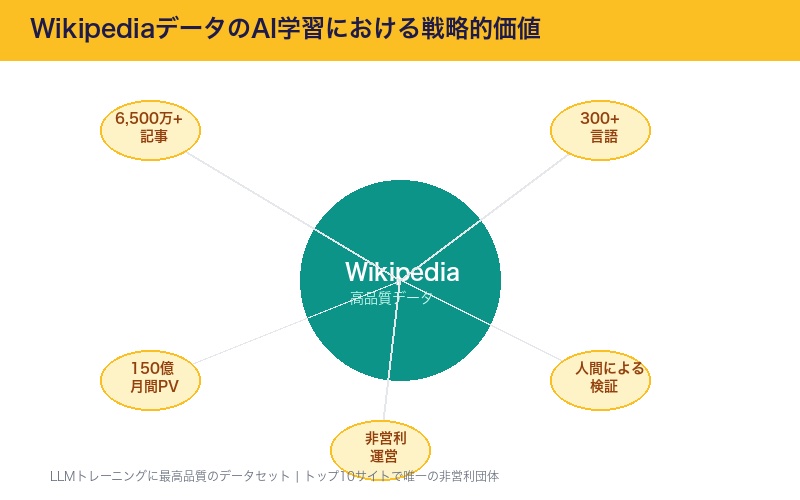
Wikipediaデータの戦略的価値
なぜAI企業はWikipediaに課金してまでデータを取得するのか。その理由は、Wikipediaデータの圧倒的な品質と信頼性にある。
| 特性 | 詳細 |
|---|---|
| 規模 | 300以上の言語で6,500万以上の記事 |
| 月間閲覧数 | 約150億ビュー |
| 品質管理 | 人間の編集者による継続的な検証 |
| 非営利運営 | トップ10サイトで唯一の非営利団体 |
| AI適合性 | LLMトレーニングに最高品質のデータセット |
Wikimedia FoundationのCPO/CTOであるSelena Deckelmann氏は次のように述べている:
「Wikipediaは、知識が人間によるものであり、知識には人間が必要であることを示しています。特に今、AIの時代には、Wikipediaの人力による知識がこれまで以上に必要です。」
「勝手にスクレイピングされる百科事典」からの脱却
この動きの本質は、AI時代における公共財の持続可能なモデルの構築にある。
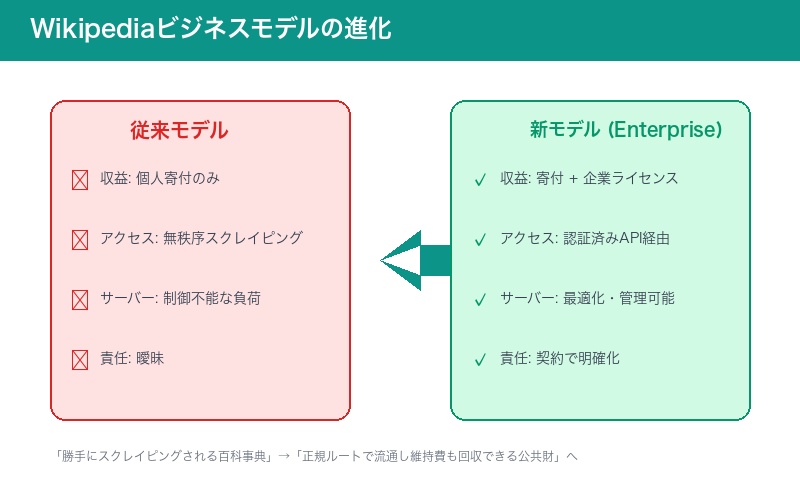
従来モデル vs 新モデル
| 側面 | 従来モデル | 新モデル(Enterprise) |
|---|---|---|
| 収益源 | 個人寄付のみ | 寄付 + 企業ライセンス |
| データアクセス | 無秩序なスクレイピング | 認証済みAPI経由 |
| サーバー負荷 | 制御不能 | 最適化・管理可能 |
| 企業の責任 | 曖昧 | 契約で明確化 |
Wikimedia EnterpriseのプレジデントLane Becker氏は明確に述べている:
「Wikipediaはこれらのテック企業の事業にとって重要な構成要素であり、企業は財政的にどう支援するかを考える必要がある。」
SEOとAI検索への影響
この動きは、SEO業界にも重要な示唆を与える。

1. 高品質データの価値再認識
AI企業がWikipediaに課金するという事実は、人間が検証した高品質コンテンツの価値を証明している。E-E-A-T(経験、専門性、権威性、信頼性)の重要性がますます高まることを示唆する。
2. AIクローラー対策の正当化
Wikipediaがボットのアクセスを制御し、有償化に踏み切ったことで、他のパブリッシャーも同様の戦略を取りやすくなった。robots.txtでのAIクローラーブロックや、有償APIの提供が業界標準になる可能性がある。
3. コンテンツの持続可能性
AIが無料でコンテンツを吸い上げ、人間のトラフィックが減少する構造は、コンテンツ制作者にとって持続不可能だ。Wikipediaモデルは、この課題への一つの解答を示している。
まとめ:データは新たな金の時代
Wikipediaと主要AI企業とのパートナーシップは、デジタル時代における知識と価値の関係を根本的に再定義するものだ。

キーポイント
- 5社の新パートナー:Amazon、Meta、Microsoft、Mistral AI、Perplexityが有償契約
- Googleは2022年から既に参加
- 背景:人間トラフィック8%減少、ボット負荷の増大
- 目的:「勝手にスクレイピングされる百科事典」から「正規ルートで流通し、維持費も回収できる公共財」へ
- 意義:AI時代の持続可能なコンテンツ運営モデルの確立
Wikipediaの決断は、単なる収益化戦略ではない。AI時代における公共財の維持と発展のための、歴史的な一歩なのだ。
そして誰もが、その分け前を求めている。データは、まさに新たな金である。
コメント